How’s y’all summer bodies lookin’? Mine’s lookin’ like I got a nice personality. — Random Reddit Post
I hope all is well with each, and every one of you. This has definitely been a stressful, and mentally trying time. Shortly after my last post, the monitor on my laptop failed, and I had to replace it! I felt like a mechanic who used to work on old cars, and had to do work on a Tesla. I would never claim to be a brain surgeon, but….. Needless to say, my laptop screen is working now. I may be going a bit batty, as you might tell from this post. I just can’t wait for the day I get to hit the climbing wall again, and boulder me some V0s. Anyways — enough of the pleasantries, let’s to get to the code.
So last we left our vector, we were able to emplace into it. We used a simple growth algorithm which expanded the capacity of the vector, when we were pushing a new value and there wasn’t enough space. We used “tag dispatching” to ensure the compiler chooses the correct constructor based on the type of the object. To do this we built the tools that allow us to look at the traits of the types, and we even learned about some neat compiler intrinsics! After I posted the article, I had a lot of great feedback, and some really in-depth discussions about an interesting take on implementing the vector. I also learned that a fair few Redditors actually use Vim for C++ development! The message was definitely received that my humor could be misinterpreted. I even contemplated for a moment, just a moment, about developing this second part of the series with Vim. Then I got stuck trying to amend a git commit, and I remembered that I’d be dead before I’d be able to figure out how to do that. It turns out you can’t teach this old Visual Studio dog new tricks.
Up next in the series was to make our vector work the STL algorithms, what I really should’ve written was some. Because it’s a huge list, and I’m not that ambitious. So I’m going to make sure it works with some algorithms, and if I have time look at implementing some algorithms.
To start, what do I mean by the STL algorithms? Well, I mean the set of algorithms defined in the header <algorithm>. If you haven’t heard of this, or don’t know of it. I strongly suggest you meander on over to cppreference.com (after you’re done reading, of course) and take a look at this useful set of functions.
The algorithms library defines functions for a variety of purposes (e.g. searching, sorting, counting, manipulating) that operate on ranges of elements. Note that a range is defined as
cppreference.com[first, last)wherelastrefers to the element past the last element to inspect or modify.
As the quote says these algorithms include a host of different operations you would want to perform on a collection, from searching, to sorting, to set partitioning. If you have an operation you want to perform on a vector or range, it more than likely already exists. So use the real thing at work, and leave the tool building to the professionals! However, that doesn’t stop us from having a little “weekend fun”, and looking at how some of these are implemented! I’ve digressed though, we’ll pick this up a little later on. I’m not one for linear plot-lines, I’m more of a Guy Ritchie fan myself.
Back to our vector — the poor thing thinks we’ve abandoned it. Last we left, it was a relatively useless container that only grew from the back. Which is all well and good, if you want to grow linearly at the back. It’s pretty useless however if you’re looking to insert anything into the middle, or trying to merge two vectors by inserting right into left. So we have to do a little work on our vector before it’s a useful container.
What do we need to do to insert? What does it mean to insert ? Well obviously, when we wrote the emplace_back function we were effectively doing a kind of insert. We were just inserting a single element, to the back of our vector. Which is pretty straightforward, if you have enough space, construct the element in place. If not, make more space, move/copy elements to the new space. Then construct the element in place. However, this is only one of the three cases of insert. When we’re inserting elements into our vector, we have three options. First, at the very front. Next in the middle. Then lastly, we could insert at the very back of the vector, which we’ve already covered.
So, with a little foreshadowing, we’ll move to the next item in the list, inserting in the middle. If we look at what made inserting at the end so easy, it was that there was never anything in our way. Sure, if we ran out of space we had to reallocate a new chunk of memory, and move things over. But nothing was ever in our way, meaning, the targeted seat we wanted to put our item never had someone sitting in it. Because we want to insert into the middle, we obviously have items in our way. Let’s use a musical chair analogy, while we attempt to figure out how to insert into our vector.

We’ll start out with our empty, 10 slot vector. It has enough space for 10 people. You can see the three pointers we manage, begin, end, and the capacity pointer. Then along comes someone to sit down.

Our begin pointer still points to the same spot, and our end is incremented. This is the placement at the back, that we worked on in the last post. Now, along comes another 5 people.
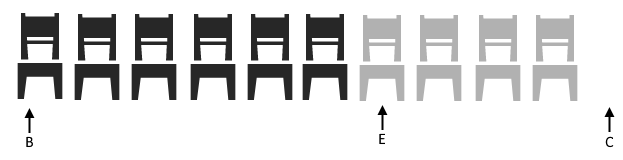
We still have capacity, so they sit at the end with no issue.
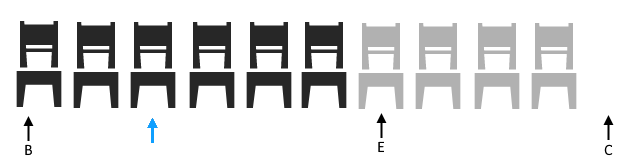
Then a group of three comes to the party, they insists on sitting starting at the 3rd slot (2nd index). What do we do?

We have to shift everyone down, starting at the blue pointer, to the red pointer (next end). Now, the chairs starting at the current end pointer, to the red pointer, are all fresh. Meaning no one has sat in them, so we don’t have to worry about them. We can just copy them forward, as we would normally, if they’re movable, we’ll move construct them. Otherwise they’re copy constructed, into their new chairs. The reason we need to do this, is because those slots are uninitialized, meaning the memory has been allocated, but we haven’t constructed anything there yet. So to figure this out, we calculated the distance between where we need to go (our new end), and our old end. That told us that three slots are free slots that need to be initialized.
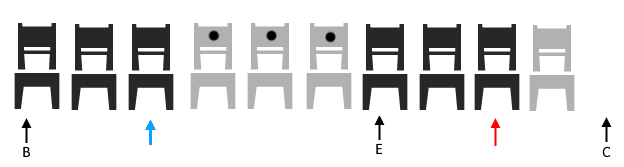
So, now we’ve got 3 empty slots next to where the new guys want to sit (our insertion point). Then we have the guy still sitting at our blue pointer. Why is he special, well when we moved those last guys, it was easy, we could copy them forward into the uninitialized memory. But the guy in blue is different. He’s different, because he has to sit in a chair where someone else has. Social Distancing Alert!!! This means we have to do something different, in real life we would need to sanitize the chair. Thankfully, in our world, we just need to call the assignment operator since the memory is already initialized. For the given distance between our old end pointer, and our insertion point, we need to copy all the items backwards. This is so we can move without overrunning our objects.
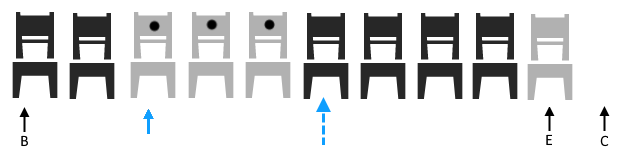
That leaves three open previously initialized slots, that we can just assign our new elements to.

After I made this infographic I realized it would’ve been super helpful to illustrate the copy backwards on more than one element. The most important thing to notes is that we need to break the moving into two distinct steps. The first is to calculate and forward create the new elements. The amount will be the count. Then we will figure out the overlap from the insertion point, to the old end, and copy that backwards. There are a few other cases depending on where the insertion point is, but I just wanted to illustrate this case. It’s really just a warm-up for understanding the next point and a big topic when working with the STL algorithms. Up until this point I’ve just been calling these arrows, pointers. Which, up until this point, has been what I’ve been using… However, I’ve been using them to step through different areas of memory, which in C++ isn’t exactly what a pointer is supposed to be used for, but technically it can be used for that. In C++ we have an object specifically used for stepping through collections.
Bingo! You guessed it, it’s called an iterator. Like a pointer, an iterator is used to point to objects, but specifically within containers. They allow us to, unsurprisingly, iterate through containers. For something like a vector, a pointer and an iterator can be analogous. Since a vector is contiguous memory, incrementing and decrementing the pointer will move you along the vector. Whereas for a container like a tree, this isn’t the case. An iterator encapsulates the traversal logic, so if you’re traversing a non-contiguous container (i.e. linked-list, map, tree, etc..), you don’t have to worry about how to traverse to the next element. You simply call increment the iterator, and it’s handled. The other thing the abstraction can give us is safety. It can do things like bounds checking, and container validation. There are also different kind of iterators, there’s Input & Ouput Iterators. There’s Forward only Iterators, Bi-Directional, and Random Access Iterators. An Input iterator is a single use iterator, and it can only be used to read. So it can be read once, and then incremented. An Output Iterator, is a single use iterator as well, but used for, you guessed it output. This lets you write into a collection. A Forward Iterator is an iterator that lets you traverse from the start to the finish of the iterator, but allows you to read more than once at each position. Bi-directional, lets you move back and fourth between the bounds, incrementing a single step in each direction. Last but definitely not least, the Random Access Iterator. It lets you basically jump around, you can increment it by any value and it will be able to move to that position. This is the iterator type that is analogous to a pointer. All of that being said if you look the Stepanov vector we used as a recipe to follow, and added our own spices, it used a raw T pointer as its “iterator”.
In order to fill substance and have more than 4 minutes worth of reading in this post. We’re not going to settle for that lame old pointer iterator. We’re going to implement our own vector, Random Access Iterator! At the time of writing this, I have not yet actually implemented it. Though, here’s my initial thought. It won’t be hard. It basically just needs to mimic a pointer… How hard can that be?
Whew…. Back, what a wild ride that was. We haven’t looked at any code yet; So let’s start by taking a look at the iterator. Like our vector, our goal is to write a simple iterator.
/*
We're going to implement a simple iterator, that uses a simple allocator,
and implments all public members of the vector on CPP reference.
Goal: It needs to function, and be just past a toy. It needs to work
with the std::algorithms.
*/
template <typename VectorT>
class vector_iterator
{
public:
using iterator_category = random_access_iterator_tag;
using container = const VectorT;
using difference_type = typename container::difference_type;
using value_type = typename container::value_type;
using pointer = typename container::pointer;
using reference = typename container::reference;
// ...
};
So when I looked at the MSFT STL vector & iterator, I’ll be quite honest — there’s a lot going on in there. A lot of which I didn’t understand. Some of which I felt would over-complicate what I was trying to achieve. To a certain extent, it’s a rabbit hole I wasn’t willing to Alice my way through. Most of it likely stems from reuse across other parts of the STL. As well, I think part of it, may be due to SCARY iterators.
Thanks to the kind redditor that pointed me in the direction of SCARY iterators; my understand is slightly deeper than shallow on the topic. Basically it has to do with minimizing the parameters on the iterator dependencies. If you look at the template argument of the iterator I’ve written, it takes a VectorT, thus when we pass vector_iterator<VectorT>, the template argument for the iterator is actually htk::vector<int, default_allocator<int>>, which makes the iterator type actually vector_iterator<vector<int, default_allocator<int>>. Previous to C++11, this would cause a compilation error, if you tried to assign a non-default allocated vector iterator to a, default iterator. Like so,
std::vector<int, non_default_allocator> v;
std::vector<int>::iterator i = v.begin();
But, apparently with the SCARY iterator changes that MSFT made in early 2012. This will in-fact compile just fine. Let’s not kid ourselves though, the toy we’re building, won’t compile. It’s a concession I’m willing to make for us.
… Ploop …
That was us coming out of the rabbit hole, and back to our own iterator implementation. As I mentioned earlier, I think, and if I didn’t then I’m mentioning it now, this iterator is a thin shim that needs to effectively behave like a pointer. What can we do with a pointer? We can increment and decrement it by some offset, or pre/post increment/decrement. We can de-reference it, or we can follow it ( operator-> ). So let’s go forth and begin.
template <typename VectorT>
class vector_iterator
{
public:
using iterator_category = random_access_iterator_tag;
using container = const VectorT;
using difference_type = typename container::difference_type;
using value_type = typename container::value_type;
using pointer = typename container::pointer;
using reference = typename container::reference;
private:
pointer ptr_;
container *vec_;
};
Without sounding like I’m beating a horse that isn’t alive, with a stick. It’s pretty simple, because we’re just building a thin shim over a pointer, that means we need a pointer. Technically, that’s all we need, but given that we’re paying for this shim, we might as well use it. We can get a bit of safety out of this thing, by hanging onto a pointer to our original container. This will allow us to do things like bounds checking, and validate we’re using iterators from the same container.
There’s really nothing surprising about this implementation so I’m only going to show a couple operators.
template <typename VectorT>
class vector_iterator
{
public:
using iterator_category = random_access_iterator_tag;
using container = const VectorT;
using difference_type = typename container::difference_type;
using value_type = typename container::value_type;
using pointer = typename container::pointer;
using reference = typename container::reference;
public:
vector_iterator()
:ptr_(nullptr), vec_(nullptr)
{
}
vector_iterator(pointer p, container *vec)
:ptr_(p), vec_(vec)
{
}
const reference operator*() const
{
assert_(ptr_ != nullptr, "empty iterator");
assert_(ptr_ >= vec_->data_.first && ptr_ < vec_->data_.last, "out of bounds");
return *ptr_;
}
reference operator*()
{
return const_cast<reference>(const_cast<const vector_iterator*>(this)->operator*());
}
pointer operator->() const
{
assert_(ptr_ != nullptr, "empty iterator");
assert_(ptr_ >= vec_->data_.first && ptr_ < vec_->data_.last, "out of bounds");
return ptr_;
}
vector_iterator& operator++()
{
assert_(ptr_ != nullptr, "empty iterator");
assert_(ptr_ < vec_->data_.last, "cannot increment past end");
++ptr_;
return *this;
}
vector_iterator operator++(int)
{
vector_iterator tmp{ *this };
++(*this);
return tmp;
}
private:
pointer ptr_;
container *vec_;
};
Some patterns I noticed in MS STL which are good practices are to implement certain operators, in-terms of the like operator. For instance operator++() and operator++(int), prefix and postfix increment operator respectively. One can implement postfix, in-terms of prefix, by simply creating a temporary copy, prefix incrementing yourself, and returning the temporary. This removes the necessity to do bounds checking in two places. Let’s use the iterator. We easily just flip the using (typedef) to use the vector_iterator and const vector_iterator appropriately, and voila we can be using it.
So earlier we went through the algorithm for insertion of an element into our vector. The signature on this function is as follows
iterator insert(const_iterator where, size_type count, const T &value)
as well there is an insert range which has a different signature taking an iterator pair, to denote a range.
template <typename It>
iterator insert(const_iterator where, It start, It fin)
For this insert overload, it takes the position, and an iterator pair to the range you’d like to insert. One would use it like this.
htk::vector<int> v;
v.emplace_back(1);
v.emplace_back(2);
v.emplace_back(3);
v.emplace_back(7);
v.emplace_back(8);
v.emplace_back(9);
htk::vector<int> v2;
v2.emplace_back(4);
v2.emplace_back(5);
v2.emplace_back(6);
v.insert(v.begin()+3, v2.begin(), v2.end());
Then we just compile it and it compiles fine. We get what we’d expect { 1, 2, 3, 4, 5, 6, 7, 8, 9 }. Next we try something a little more complicated. Well, it’s not complicated, it’s just we’re mixing our two insert calls.
htk::vector<int> v;
v.insert(v.end(), 4, 1);
htk::vector<int> v2;
v2.emplace_back(1);
v2.emplace_back(2);
v2.emplace_back(3);
v.insert(v.end(), v2.begin(), v2.end());
We compile this… Wham! Illegal indirection. Wait — what does Illegal Indirection mean? From MSDN
Indirection when operator ( * ) is applied to a non-pointer value.
Compiler Error C2100
Wait — how can that be? I’ve obviously passed iterators, see v.insert(v.end(), v2.begin(), v2.end()); If you look closely, both inserts are the same amount of arguments, one takes 2 template arguments, and the other takes a size_type, and a T. But in our case T is int, and the value we’ve provided for size, 4, just so happens to be an integral literal which is an int. So, both of the arguments just so happen to match both signatures, so the template signature is chosen, because it’s closer. When the template signature is chosen, at some point we’re trying to dereference an iterator, which has been assigned the value 4. So what do we do?
If you recall from the last post, I mentioned in passing this thing called SFINAE. Then, I promptly took a right turn to avoid it, and we used a similar, but tastier concept called tag dispatching. Well, I must’ve taken 3 more right turns, because here we are again… The reality of this situation, is that we want the compiler to “test” whether or not this is the right function, and have that “test” not be an error. If it fails the test, the compiler will just carry on looking for an appropriate match. With simple glasses on, this is what SFINAE is. It stands for Substitution Failure Is Not An Error, it means that when a template substitution fails, it doesn’t generate a compiler error. This can be used to decorate functions, so that depending on the compiled type_traits, different functions can get called.
The canonical example, from Wikipedia:
struct Test {
typedef int foo;
};
template <typename T>
void f(typename T::foo) {} // Definition #1
template <typename T>
void f(T) {} // Definition #2
int main() {
f<Test>(10); // Call #1.
f<int>(10); // Call #2. Without error (even though there is no int::foo)
// thanks to SFINAE.
}
Let’s look at an example I cooked up.
// Type your code here, or load an example.
#include <string>
#include <iostream>
#include <type_traits>
template <int value>
constexpr bool is_three()
{
return value == 3;
}
template <int value>
constexpr bool is_three_v = is_three<value>();
template <int value>
std::enable_if_t<!is_three_v<value>> foo()
{
std::cout << value << std::endl;
}
template <int value>
std::enable_if_t<is_three_v<value>> foo()
{
std::cout << "three" << std::endl;
}
int main()
{
foo<1>();
foo<2>();
foo<3>();
foo<4>();
}
and just like that you get!
1
2
three
4The idea is that you plan your substitution failures, so that one function will resolve to a better match, and in this case, one function will resolve at all at any given time. Often, to help with SFINAE, library programmers will use meta-programming tools like std::enable_if to enable SFINAE. Under the hood, it looks something like this.
template <bool Eval, typename T = void>
struct enable_if {};
template <typename T>
struct enable_if<true, T>
{
using type = T;
};
template <typename T>
using enable_if_t = enable_if<T>::type;
If you look at the Wikipedia example, it uses the failure of T::foo as a failure, to fallback on the other function. With enable_if, if the evaluation is true, there is a type defined, if not, nothing. This allows you to put an enable_if where you would regularly use a type, and if it the evaluation is false, the substitution failure will continue. If we pop back to what we were doing.
template <typename It, htk::enable_if<htk::is_iterator_v<It>>>
iterator insert(const_iterator where, It start, It fin);
In our case, we only want to enable this insert call if, well if the type were passing is an iterator. We need to implement is_iterator_v. How do we go about doing that? We need some way to check if the type has something that indicates it’s an iterator. What makes an iterator unique? Looking back at the iterator, it defines some specific….characteristics. Yah — characteristics. So one of the characteristics is the iterator_category that this thing is. This tells us what kind of iterator it is. Any iterator should have this, so we can implement our is_iterator_v with that in mind.
template <typename T, typename = void>
struct has_iterator_cat : false_type {};
template <typename T>
struct has_iterator_cat<T, void_t<typename T::iterator_category>> : true_type {};
template <typename T>
constexpr bool has_iterator_cat_v = has_iterator_cat<T>::value;
template <typename T>
constexpr bool is_iterator_v = has_iterator_cat_v<T>;
You may notice the void_t on the specialization; I’m not 100% on my understanding of why it is needed, but it is as follows. When the compiler tries to instantiate has_iterator_cat<T>, it can either instantiate the specialization, or fall back to the default. With the void_t it will either be able to evaluate the expression thus completing the specialization, or it will fail, and fall back to default. Depending on which gets instantiate, we land on true_type or false_type, giving us the appropriate value for our type. Now we can apply this gently to our insert function, and our code will compile.
I said earlier that pointers acted as iterator, and denote ranges, so we should be able to do something like this.
htk::vector<int> v;
v.emplace_back(1);
v.emplace_back(2);
v.emplace_back(3);
int arr[3] = { 4, 5, 6 }
int *b = arr;
int *e = b+3;
v.insert(v.end(), b, e);
Then we hit compile, and get a compile error, “cannot convert int* to size_type“. Obviously, we did something wrong. Pair programming problem. 🙂 What did we do wrong though? Let’s take a look at what our rule we defined. We said, if the T::iterator_category was true, then we would enable the function. When we’re passing b, what is its type? int *. Oh – kay. int * obviously doesn’t have an iterator_category, so the SFINAE evaluation is failing and it’s using the other insert function. Let’s fix that, we’ll just go to the definition of int *, and add iterator_category like we did to our own iterator. Uhh — what? You mean we can’t just go change the definition of int *?
Did you pick up on my subtle foreshadowing before in the post? These properties about iterators, I called them characteristics. I was specifically trying to avoid the word traits, so that I wouldn’t give away everything at once. So we can illustrate why we need iterator_traits. Before, when we wrote our type_traits library, it was a collection of classes to distinguish properties of types at compile time. Because we can’t directly modify int *, we can create something that describes the iterator traits of a pointer.
Side note: this is one of the most powerful parts of the STL. The ability to be extensible without modification. i.e. the Open-Closed principle. The library is very open for extension, meaning you can easily make your classes work with it, and closed for modification. Meaning you don’t need to open the thing up and changes its guts to enable extension.
We need to create a small set of helper classes, that will describe these traits about our iterators. That we can then use to check if an object is an iterator. We need iterator_traits!
template <typename, typename = void>
struct iterator_traits
{
};
// uses SFINAE to overload if iterator has the traits.
//
template <typename Iterator>
struct iterator_traits<Iterator,
void_t<
typename Iterator::iterator_category,
typename Iterator::difference_type,
typename Iterator::value_type,
typename Iterator::pointer,
typename Iterator::reference >>
{
using iterator_category = typename Iterator::iterator_category;
using difference_type = typename Iterator::difference_type;
using value_type = typename Iterator::value_type;
using pointer = typename Iterator::pointer;
using reference = typename Iterator::reference;
};
template <typename T>
struct iterator_traits<T*>
{
using iterator_category = random_access_iterator_tag;
using difference_type = htk::ptrdiff_t;
using value_type = T;
using pointer = T*;
using reference = T&;
};
template <typename T>
struct iterator_traits<const T*>
{
using iterator_category = random_access_iterator_tag;
using difference_type = htk::ptrdiff_t;
using value_type = T;
using pointer = const T*;
using reference = const T&;
};
We start out by defining our base case, this has no traits whatsoever. So if you instantiate iterator_traits<Foo>, you get no members thus no traits. Which makes sense, because Foo is not an iterator. Second, we have this massive specialization, using that void_t trick, to check that the type has all the correct iterator members. If it does, they use to the trait typedefs, which expose the iterator types themselves. Next, we have the pointer specializations, which give us our traits for pointers. Which is exactly what we needed for this scenario. Then we just have to change our has_iterator_cat, to use the iterator_traits.
template <typename T>
struct has_iterator_cat<T, void_t<typename iterator_traits<T>::iterator_category>> : true_type {};
After this change, our compiler stops complaining, and our insert function now works with pointers! What a ride! As to not inundate the reader, I’m going to start wrapping this post up. Let’s take a look back and see how far we came. I wanted to explore getting this vector to work with some STL algorithms. To do this, we had to look at building an iterator for our vector. Because the STL algorithms work on iterators. We really didn’t need to, since our original pointer iterator would’ve sufficed. Meaning, our vector already worked with the STL algorithms.
To summarize our adventure. We learned how the insert function works, by creating space within the middle of our vector. It does this, by moving the trailing items into the uninitialized space, and then move-copying backwards any items that overlap already used space. Then we took a look at creating an iterator, and then lastly implementing our range based insert, so that it works with pointers and iterators. We learned about SFINAE, and how we can use it to choose which function the compiler should use. We also learned, hopefully, that implementing a real deal STL is a lot of work. If you think about it, we’ve implement one container (partially).
The code is available at my Github, and I’ll leave it as an exercise to the reader to implement the reverse_iterator, and test out the vector with some STL algorithms.
In the next post, I’m going to pit my little vector against the MSFT STL vector. It’ll be very interesting to see how it fairs. As well, who knows, maybe we’ll take a crack at implementing some algorithms, since I didn’t get a chance to this time.
Until then, Stay Healthy and Happy Coding!
PL
Some beautiful paths can’t be discovered without getting lost.
Erol Ozan
References
Dining room, chair icon
https://devblogs.microsoft.com/cppblog/what-are-scary-iterators/
https://riptutorial.com/cplusplus/example/3778/void-t

Leave a comment